Copyright 1998 Simon St.Laurent
The last 50 years of computer development have seen dramatic changes in the way data is stored, processed, and interpreted. Punched cards gave way to magnetic tape, which then gave way to disk drives, hard drives, and other media. As the volume of information has grown and its accessibility increased, developers have created new ways to access and manipulate that information. While these techniques have vastly improved computers' abilities to locate and retrieve information, they still tend to store information in large, undifferentiated blocks. Improving access to information within the typical 'file' requires another enormous leap, applying the techniques developed for managing structured information to the relatively unstructured world of human documents.
From the earliest days of computing, it has been clear that computers work best on information structured to meet their needs rather than those of humans. Taking full advantage of the enormous processing and storage capacity of computers has required the adaptation of 'natural' (mostly human) structures to serial, hierarchical, or tabular forms that computers can manipulate. Most of the progress in computer-human interaction has come from the development of tools that map human structures on to forms that computers can handle. This can be seen in tools from high-level languages that compile into computer-friendly bytecodes to graphical user interfaces that convert human actions on a set of metaphorical objects (like folders, windows, or the 'piece of paper' that appears in many word processors) into actions for the computer to perform.
Filesystems have been built from the beginning to maximize access speed while preserving the integrity of the data they contain. The earliest file systems were flat lists of files and the locations where their data was stored. Later systems applied tree structures learned from years of hierarchical database development to create directory structures. A directory (often displayed as a folder in a GUI) is a container for other information. Directories may hold other directories, or files - pointers to collections of information. (File systems often hide the low-level details of data manipulation from users and developers, preferring to consider the physical storage of bytes as separate from the organization of the data they contain.)
Many filesystems have grown extremely elaborate, offering users a variety of shortcuts, aliases, and pointers through the hierachical maze, making it easier for users to reach their information quickly. The basic purpose of a filesystem, however, has remained the same - to provide structures that assist humans in finding files in the confusing world of physical data storage. Interpreting those files is a task handed off to other programs, themselves often stored in the file system, which use the file system for access to the information. The structure of the files varies widely, leading the file system to treat files as black boxes. Some systems can attach to a file system and provide content-based searching, but so far these tend to be programs themselves, separate from the underlying file system and provided with a basic understanding of certain types of file content.
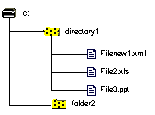
Neatly structured file systems often contain a riot of wildly different file structures. Word-processing documents, spreadsheets, graphics, programs, and databases coexist peacefully despite their mutual incompatibility. The level of structure in these documents varies dramatically, from the carefully-maintained table systems of a relational database to the chaos of a typical 'fast-saved' word processing document or the serial listing of a compiled program. Figure 1 shows a typical directory of documents as they may be accessed in a traditional file system.
Figure 1 - Typical File System
Each of the files at the bottom of the tree is a complete unit in itself, assigned to a particular application for processing and interpretation. As far as the filesystem itself is concerned, those files are black boxes, large series of bytes that can be passed to an application when needed.
Database systems often bypass file systems entirely, preferring to be assigned a partition of their own in which they can manage data directly, without the overhead or intervention of a file system. Since the data units in a typical large database are often small, and because efficient maintenance of tabular (and other) structures is critical to performance, databases often choose to handle an extensive amount of low-level storage management that smaller-scale applications leave to the file system.
Whether data is stored as binary objects in a file system or in a specially-built database storage structure, a key problem remains: gross incompatibility between the data produced by different programs. A small industry has arisen to create file conversion tools, and to allow applications to work cooperatively - usually one inside another - to get around this problem, but the opportunity costs of this incompatibility are far greater than simple inconvenience.
Moving away from unique file formats toward a more generic model offers users (and developers) a new way of working with data that provides far more flexible data handling while allowing users to escape the traps of proprietary file formats. Some large document-management systems have already done this to a certain extent, using SGML and database systems to organize large collections of data, but the efficiency gains have so far been realized primarily on very large-scale projects.
XML promises to bring these efficiencies to projects operating on a much smaller scale. The simplicity and syntactical rigor of XML make it easy for both humans and computers to understand. While its structures still reflect the needs of programmers more than the needs of humans (mostly because of its strict rules for nesting elements), XML has promise as a generic file format for many different kinds of documents, from CAD documents to databases to word processing files and spreadsheets. Digitized multimedia information remains outside of its grasp, but these can be stored in other structures that connect to XML quite easily, using XML-Link and other developing standards.
XML is definitely a markup language designed for easy interpretation by machines, with strict rules for nesting structures and a syntax for defining document structures. Nonetheless, its design is much more promising as a file format for human documents than many of its predecessors. The files themselves can be designed for human-readability, using intelligible, meaningful tags instead of the numeric codes that have defined many previous formats. More important in the long run, most likely, is the extreme openness of XML, which makes it easy for a large number of programmers from a diverse set of backgrounds to evolve tools that transform these tightly hierarchical structures into documents approachable by humans. (For the most part this won't be a difficult task, but getting around XML's refusal to overlap tags will take some programming.)
XML's promise lies mostly in its extensibility. Because XML defines a way to create tags rather than just a set of tags, XML can be used to create tag sets for a wide variety of structured and unstructured data types. Because XML's element and attribute structure maps easily to existing object-oriented programming structures, building applications that use this format is relatively simple. Documents can effectively provide their own data and content structures, without relying on the intervention of an outside application. Multiple applications can interpret the same structure and present it in different ways. Elements and attributes can provide labels for a wide variety of data types, indicating content type, source, privileges, and descriptive information.
For instance, a document containing epidemiological information can be used by one application to generate a graph, by another to create tables, by another to create a map indicating the geographical location of cases, by another to build a timeline, and by another to build a simulation. Instead of using a monolithic application to produce these results, or cutting and pasting among applications, users can apply assorted components to the same set of information to get the results they need - perhaps saving a companion document to the main XML document that specifies the formatting the user chose for particular output, or for a run of the simulation. Using this approach, all the data in the document (or sub-document) is available to applications, which may process it selectively to meet user requests.
The structural information provided within a document also promises to provide a new, more flexible way to allow applications (components, more likely) to work with each other. A system with a namespace that specifies which components should be used to handle particular elements would make it much simpler for a program to use a certain kind of viewer/editor for information in an EDITABLETEXT element, another for information in a SPREADSHEET element, and yet another for information in a DIRECTORY or GRAPHIC element. This approach is a bit more limiting, restricting the use of certain information to certain applications, but may be necessary in the short term at least and in the long term for certain types of information.
XML also provides a set of tools for linking documents and subdocuments. Perhaps most important, XLL (extensible linking language) allows users to specify links between documents and sub-documents, based on the structures inside the document. Attributes or element content can be used to specify the portion of a document needed, or the location of a particular element within a document may be used to determine its inclusion in a link. Links can also be multidirectional, making it possible for multiple users of information to determine what links have been established that connect to their data as well as the links they have created going outward.
This combination of extreme openness, fixed structure, and the regular need for portions of a document suggest that it's time for a new approach to file systems, and perhaps even a new approach to operating systems. Systems that use XML as their file type can expand the hierarchical reach of the file system beyond the boundaries of documents and allow the storage and retrieval of information on an element-by-element basis.
A typical (and very simple) scenario might involve a document with multiple subsections that a large group of people are working on collaboratively. An author might need to work on section 5.3.2, which depends for much of its means on section 5.3.1 preceding it and section 5.3.3 following it. Using this system, the author could open section 5.3.2 for editing, with read-only copies of 5.3.1 and 5.3.3 available simultaneously for reference and linking. This system could allow multiple authors to work simultaneously; if changes were made to section 5.3.1 while the read-only copy was open, the librarian (the object store) could send a message to all the users who had checked out 5.3.1, updating their copies with the latest information and alerting them to the changes. Version control and access control become built-in functions of the document system, rather than manual processes run by cut-and-paste, panicked examinations of date modified, or the check-in and check-out of entire documents, locking out other users.
Implementing this requires a drastic rethinking of the file system and database structures as well. Supporting retrieval at the element level breaks down formerly monolithic binary files (or, in database terms, Binary Large Objects or BLOBs) into separate, often tiny chunks which may themselves continue other chunks, which contain other chunks, and so forth. At this point, the file system is no longer a file system in the traditional sense, but an object store which is capable of storing large chunks of information as well as hierarchies built of tiny data sets. The document still exists - but only as one layer of the object store, an object containing other objects much as directories contain files at present.
Figure 2 shows what this broken-down system might look like, providing programs direct access to information many levels below that provided by the files of the previous system.
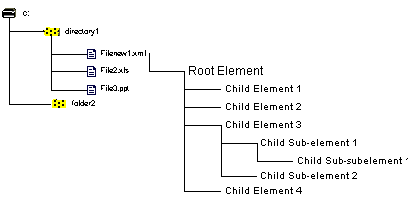
Figure 2 - Enhanced, 'Deeper' Filesystem.
Once broken down in this fashion, data is readily available for manipulation, modification, and selective retrieval. Versioning becomes a simple matter of defining a set of elements, and storing discarded information until it becomes time to purge. XML links can retrieve information efficiently, combining and recombining data without the overhead of poring through files to extract the right piece. Object stores may be placed on servers for ready access to a wide variety of browsers, applications, and output devices. Traditional database queries as well as full-text search systems can index and retrieve information more efficiently, receiving contextual clues from element structures that didn't exist in previous document structures (like HTML.)
Versioning and access control open their own set of difficulties, especially when both are managed at the element level. This information needs to be stored in a separate layer of meta-information by the object store, in a format which can be merged with the XML information itself (to present multiple versions, for instance, or to list the people who can see a document) when necessary. Object stores can handle this fairly transparently, storing the version and access information alongside the element and attribute information, but incorporating it into the XML only when requested. Once this information is in the object store, it can provide the object store with an additional layer of intelligence about the document, allowing it to act as a gatekeeper, providing appropriate one-at-a-time edit access to portions of the document while keeping the document open to many more authors, editors, and readers than were previously possible.
The model of the Web server as an interface to a file structure was useful in its time, but now seems like an intermediate step. The transports and interfaces pioneered by the Web will undoubtedly continue to remain key underpinnings of network computing, but the operating systems underlying the Web server are becoming roadblocks. XML's impact is more than an end to the browser wars or the provision of a convenient interchange format; XML is a radical surgery on the style and use of documents that have served us well for so long. By stripping down to the bare essentials of computerized information storage, XML makes it possible for developers to create tools which will open that information up to users in more flexible, more accessible, and even friendlier ways.
To a certain extent, this new structure makes possible many of the grander claims made by the promoters of Network Computing. In the XML object store model, all data resides in an object store which may be centralized and easily managed, making it much easier for thin clients to be built without much local storage. (Object stores may also be distributed, even to the local level, if the situation calls for it, though at a certain cost in efficiency.)
Client machines need only a means of reaching centralized object store data and manipulating it, preferably a means that understands networks well. At this point in time, either Microsoft's Active X and DCOM, or Sun's Java would work. Because of Microsoft's powerful attachment to the previous PC model of computing, as well as its frequent promotion of proprietary tools, this paper will consider only Java as a means for creating this object store-based network. This does not exclude Microsoft's clients, servers, or even its Java Virtual Machines, provided that they can run Java applications built for this system.
Choosing Java also makes it much easier to include a wider range of client and server architectures, from Apple Macintoshes to Sun Sparcstations to IBM S/390 mainframes. This architecture does not require the creation of an entirely new operating system; instead, it relies on Java to provide the glue between a wide variety of existing machines and open them to a different style of cooperative network operations. Windows NT servers, UNIX servers, AS/400s, and S/390 mainframes should all appear identical to the client machines, except, of course, for their ability to deal with different loads.
Clients using this model are much more than terminals passing keystrokes and mouse movements to a central server - they run Java applications and applets (which are run locally and may also be stored locally if appropriate) in cooperation with Java applications and servlets on the servers. The Java applications can gather data from the object stores, manipulate it locally, and pass it back to the object store in modified form. Because the information is stored in a generic format that is easily stored and easily manipulated, it can be passed from application to application and computer to computer quite easily.
Clients for this system require only a Java virtual machine (and that, technically, could be replaced with another system, as long as it could communicate). This could be an NC-style system that contains only the code to boot itself up and contact a server for software, or it could be a full-fledged PC with applications built to reference the data on the object store. Ideally, a Java class would provide functionality much like that offered by the current File menu on most GUI systems, plugging into programs and providing them with easy access to the XML (and binary) information on the object store. A desktop-like program could also provide access to applications and applets on the object store, making it easy to run code from centralized locations. The desktop functionality could run on top of HTTP or a similar protocol for maximum compatibility with older web applications.
Servers in this network are of two types: action servers and object stores. Technically speaking, an object store is just an action server that stores large quantities of information in an object database, but for most purposes the two types of machines will be optimized for particular needs. Object stores will need large quantities of permanent storage, as well as backup facilities and a considerable amount of memory for servicing multiple requests and caching data, while action servers will need only a small quantity of permanent storage but large amounts of memory. Action servers cross the boundaries between clients and servers; an action server is essentially a client capable of running much more demanding applications. Action servers will receive hits from many users rather than interaction from a single user. Both clients and action servers will expect most of their information to come from dedicated object stores.
Object stores are essentially intelligent replacements for file servers. An object store could be constructed from the ground up, or, more likely, could be a Java front-end for an object-oriented database, like Poet, Jasmine, or a similar system. It could even be a relational or object-relational database, though performance would suffer. An object store server provides an interface between clients making requests and the actual API or OQL (Object Query Language) calls for the particular object database solution being used. Ideally, the object store would remain something of an abstraction, a general term used to refer to an object database with an appropriate front end that could run on a variety of operating systems and/or database platforms. The object store as a whole must be able to accept and deliver XML and binary information efficiently, providing additional versioning and access control services as required.
An 'application' in this context is a fairly shapeless cloud. Instead of programs, computers provide only services with clearly defined interfaces, much like multi-tier client-server programs do today. Performing a task could be a simple matter of a client interacting with an object store or a more complex matter of a client harnessing many action servers which interact with object stores to produce the desired results. Apart from the usual (large) issues of security, all services in this scenario are peers, capable of contacting each other to perform tasks. Choosing which machine should run a given service is a matter of administrative convenience, matching up the right computer and location in the network with the task. A key application would likely be directory services (perhaps implemented via LDAP or through an object store of their own), helping client machines find their appropriate servers as needed.
A very simple network of heterogeneous clients and servers might look like Figure 3. All machines are assumed to be running Java Virtual Machines, using RMI, HTTP, or a sockets interface to trade XML-based information.
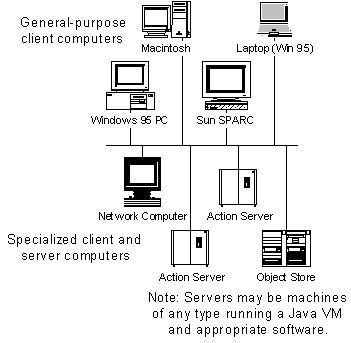
Figure 3 - Clients and Servers in an Object Store system
The object store model presents a significant disadvantage for certain types of applications which deal with large quantities of binary data, mostly graphics and multimedia applications. For these situations, the object store should offer more traditional-seeming file storage facilities, storing these binary files as large objects among the more finely fragmented text and numeric records. In this case, the traditional (thick) clients have a distinct advantage over network computers and other thin clients. Using appropriate clients for appropriate tasks should keep user rebellions from igniting. The ability to store large binary objects will also make it easier to store programs for client (and action server) execution.
In many ways this system resembles the data warehousing and multi-tier client/server schemes which are already in development, but there are some significant differences. First, the object stores provide information that is usable (thanks to XML) for a wide variety of different applications. The use of an object store also makes it easier to integrate data from a wide variety of different sources, from word processing files to spreadsheets to geological data. Multiple data models may be represented easily, avoiding the trap of tables presented by relational systems. XML's linking mechanisms provide a convenient means of reducing data redundancy, providing higher efficiencies when combined with an object store that can provide them full support. Finally, processing may take place at any point in the interaction between the client and the object store, depending on the services used to connect the two.
The object store also presents some advantages for searching and processing data. Object stores spread over a wide-area network (WAN) could be accessed more efficiently, processing requests for searches and retrievals by itself (or with the assistance of a LAN-connected action server), returning only the information needed to the user. In most of the current file system world, file searches over WAN connections are painfully slow operations, requiring massive traffic flows between the client and server over networks with little spare bandwidth.
At the same time, the object store opens up new levels of file and element access control. Because an object database is capable of storing many different levels of access permissions and sub-permissions, assigning precise permissions to information is much simpler than it is with a traditional filesystem or relational database. A user could be given permissions to read and modify one section of a file, and the read the rest of it, while not having the right to add sections or modify material outside their area of control. File/record locking can benefit from such granularity as well, making it easier for multiple users to share and modify a document simultaneously. Users could be assigned the right to modify only a certain number of a particular element, keeping users from opening entire files for read/write access when they only need a segment or two. Presented with a request to open a file or element, the object store could check privileges, set file locks, and return the appropriate information, or (if the request failed), a map showing information the user could access: "I'm sorry, Chapter 2 is opened by another user, but Chapters 3, 5, and 7 are available for editing."
Finally, this systems doesn't necessarily exclude the use of either traditional filesystems or relational databases. Apart from the need to support legacy resources, there may remain situations in which these tools (especially relational databases) remain appropriate. Highly structured transactional information will still be handled better by a relational database than by an object store. Action servers could provide XML translations of such information if necessary, connecting to the RDB with traditional SQL calls and making the conversion.
Comments? Suggestions?
Please contact Simon St.Laurent
Some of my other XML essays are also available.
Copyright 1998 Simon St.Laurent